Nat. Biotechnol. | 高歌课题组提出单细胞多组学数据整合与调控推断新方法
基因的转录在生物学中心法则中处于承上启下的重要环节,与相对“静态”的基因组相比,转录组在不同组织/器官/发育阶段均有显著变化,是细胞完成相应生理/病理功能的重要生物学基础。细胞是构成生命的基础单元,迅速发展的单细胞测序技术为在单细胞层面研究细胞功能及其背后的基因调控机制提供了重要的技术手段,单细胞测序可用于检测多种不同的组学种类,包括转录组、染色质开放组、DNA甲基化组、组蛋白修饰组等等,对不同组学技术产生的数据进行整合分析有助于更全面地刻画细胞内的基因调控状态、揭示调控机制。然而,与传统的bulk数据相比,单细胞数据具有规模大(百万级细胞)、噪声高(dropout, batch effect)、异构性强等特点,如何通过开发新的计算方法实现对这些宝贵数据的有效利用已成为当今生物信息学领域关注的重点与热点。
针对上述挑战,2022年5月2日,北京大学/昌平实验室高歌课题组于Nature Biotechnology发表题为Multi-omics single-cell data integration and regulatory inference with graph-linked embedding的研究论文,提出了基于图耦联策略的深度学习方法GLUE,首次实现了对百万级单细胞多组学数据的无监督精准整合与调控推断。

单细胞多组学数据整合的一大挑战在于不同组学的特征空间存在差异,例如转录组的特征是基因,而染色质开放组的特征是染色质开放区段,不同特征空间的细胞缺乏可比性。为了解决这一问题,GLUE提出了全新的图耦联(graph-linking)策略,将组学特征间的先验调控关系表示成引导图(guidance graph)的形式,其中节点为组学特征,边为组学特征间的先验调控关系。模型采用变分图自编码器(Variational Graph AutoEncoder, VGAE)学习组学特征的低维表示作为组学数据的解码器权重,从而将不同组学的低维隐空间表示关联起来并确保其“语义一致性”;在此基础上,GLUE进一步引入对抗学习以消除不同组学降维表示之间的系统性差异(图 1)。
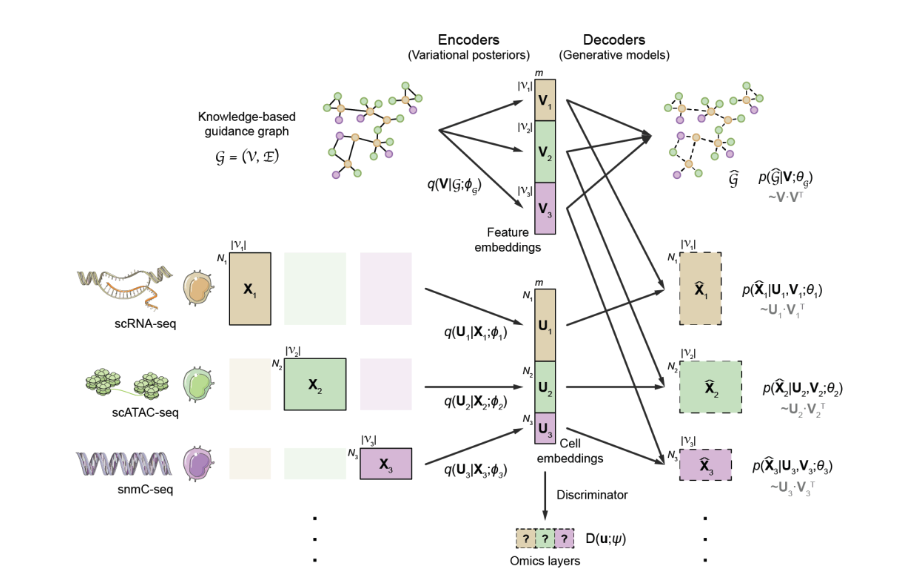
图 1 GLUE模型的结构示意图
与其它方法相比,GLUE的主要优势包括:
1. 多组学整合的精度高:多个单细胞转录组与染色质开放组数据的整合评测显示,GLUE无论是在细胞类型层面和单细胞层面,相比已有单细胞多组学整合算法具有更高的整合精度(图 2a–c);
2. 对于先验调控知识具有鲁棒性:GLUE引导图中使用的先验调控关系无需特别精确,以单细胞转录组与染色质开放组数据整合为例,只要将染色质开放区段与临近基因相连就可以构建有效的引导图,噪声实验表明即便对上述引导图添加大量随机扰动,GLUE仍能得到正确的整合结果(图 2d);
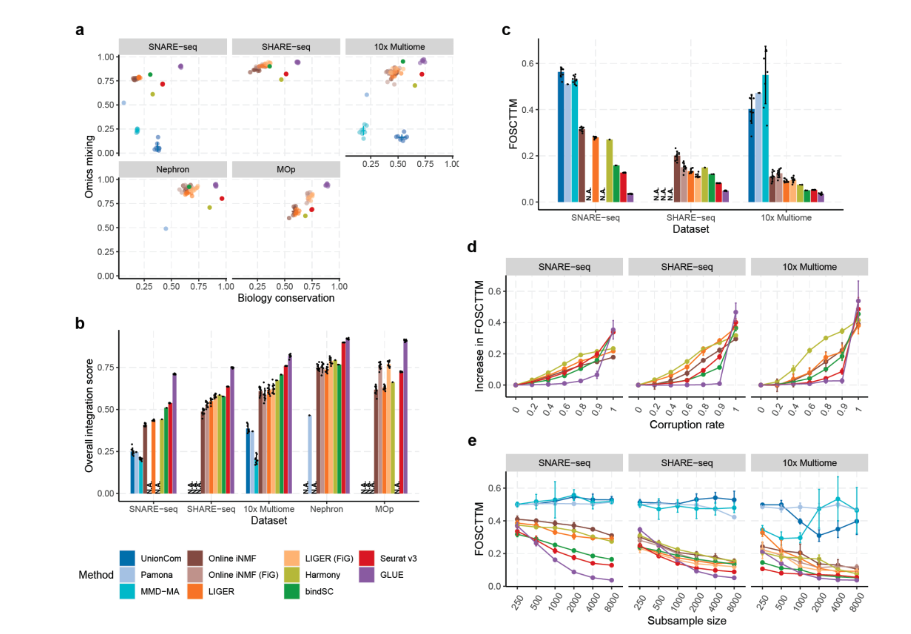
图2 GLUE的多组学整合性能评测结果
3. 具有较高的计算可扩展性(scalability):GLUE的计算复杂度与细胞数之间呈亚线性(sublinear)关联,是同类方法中唯一可以精准分析上百万单细胞的方法(图 3);

图3 GLUE首次实现了图谱级超大规模单细胞多组学数据的准确整合。与同类工具相比,GLUE在细胞分辨率与叠合精度方面均具有显著的优势
4. 可支持任意数量、调控方向的组学数据:通过引入组学特异的变分自编码器(Variational AutoEncoder, VAE)组件堆叠,GLUE支持对多组学非配对(unpaired)数据的无监督整合。作者成功用其整合了小鼠大脑上皮的单细胞转录组、染色质开放组和DNA甲基化组,并显示了三组学整合可以有效地改善细胞的类型注释。与此同时,GLUE在设计上引入了模块化思想,可容易地进一步扩充以支持如单细胞Ribo-seq、空间转录组等更多组学类型数据整合;
5. 可同时进行调控推断:除了细胞层面的跨组学匹配,由于GLUE在先验调控图中直接对调控关系进行了建模,还可综合先验调控信息与多组学数据统计相关性,实现可靠的转录调控推断,作者以外周血数据集为例,应用GLUE整合了pcHi-C物理相互作用、eQTL突变表型关联、以及单细胞转录组与染色质开放组资料,并证明GLUE可有效整合多种调控证据以得到精准的调控关联(图 4)。值得指出的是,GLUE引导图所需的先验调控关系无需特别精确(以单细胞转录组与染色质开放组数据整合为例,只要将染色质开放区段与临近基因相连就可以构建有效的引导图),系统的评测显示GLUE多组学整合与调控推断均具有较强的鲁棒性。
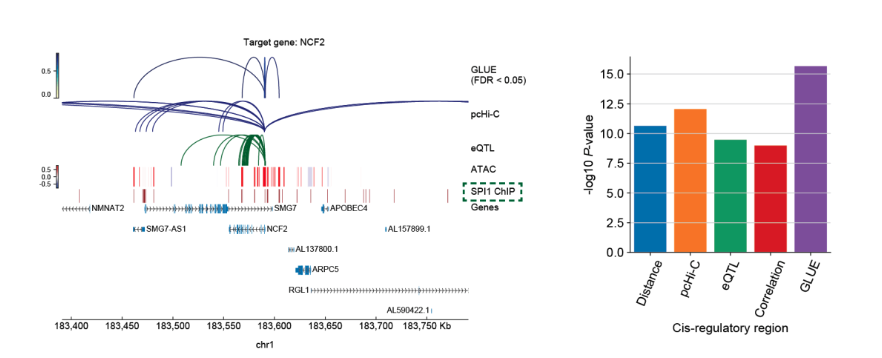
图4 GLUE可综合先验调控知识与单细胞多组学观测进行可靠的调控推断。
GLUE全部实现代码已经开源发布(https://github.com/gao-lab/GLUE),可通过PyPI和Anaconda平台直接安装使用。
博士生曹智杰为该论文第一作者,高歌研究员为该论文通讯作者。该研究得到了国家重点研发计划、蛋白质与植物基因研究国家重点实验室、北京未来基因诊断高精尖创新中心和昌平实验室的资助。计算分析工作于北京大学高性能计算校级公共平台和北京大学太平洋高性能计算平台完成。
论文链接:
https://www.nature.com/articles/s41587-022-01284-4